Exploring AI? Don’t try boiling the ocean

Everyone is searching for opportunities to leverage artificial intelligence (AI). To date, relatively few opportunities identified in regulatory and quality areas seem to be paying off.
Some efforts have focused on voice-initiated queries: “Hey Google, will I need to file a variation in Chile if I change environmental controls in the packaging area?” Others have focused on extracting what could be structured product data embedded deeply within submissions documents in preparation for eventual Identification of Medicinal Products (IDMP) implementation. One company explored AI as a means of mapping their dossier in the hope of identifying redundant content and consolidating to a more concise submission. Of the dozens of such attempts this author has witnessed, none has proven an unqualified success.
Part of the problem is lack of focus. In each case, the AI solution was trying to boil the ocean, in terms of breadth of content or breadth of process. Focusing on a more narrow range of data and limited number of process steps can yield a more rapid, and discernible, return on investment. One approach is to draft a clear “use case,” which can include an articulation of the business problem, a detailed description of the end-to-end solution and quantification of the expected benefit.
A few definitions
Before discussing some enticing use cases, a few definitions are in order. Automation does not necessarily include machine learning. Robotic Process Automation (RPA) can be as simple as a few lines of code to automate repetitive tasks such as extracting text from email forms and entering the data into defined fields. As long as the data arrives properly structured, RPA can greatly increase speed and quality of the transfer process.
As we move up the sophistication scale, machine learning enters the picture. Natural Language Processing (NLP) learns context through studying many (often thousands) of sample documents. An example would be learning to distinguish among inspection findings, health authority Q&A and approval documents. As the system continues to learn, it might recognize commitments and automatically enter the information into a Regulatory Information Management (RIM) system. Natural Language Generation (NLG) does the reverse, taking data in tabular form and generating narrative, such as creating a clinical study report from Electronic Medical Records (EMR).
Artificial Intelligence ultimately mimics (or surpasses) tasks that a human can perform. NLP and NLG work with blocks of text, either interpreting context and meaning or creating narrative. AI can also be applied to analyzing and applying structured data. For example, product registration metadata, such as product type, health authority and date/time stamps can generate insights (predictive analytics) and automatically update algorithms to inform more accurate forecasting and resourcing decisions.
Health authority expectations
“Regulatory intelligence” relies on much more than just access to published regulations. Health authority expectations are embedded in all manner of interactions: pre-submission meeting minutes, Response to Questions (RtQ), inspection findings, approval letters and so forth. Companies that can readily and reliably surface relevant documents are able to craft better submissions and respond to similar questions much more efficiently.
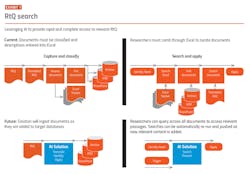
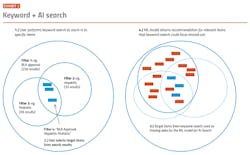
One large global biopharma company we are working with has focused its AI efforts on applying intelligent search to past RtQ for better understanding of health authority expectations. The current approach is to collect, read and assess every question and answer exchanged between the company and health authorities, and enter the topic and a link to the original document in an Excel worksheet. The work is time-consuming and provides restricted value due to the limits of classification.
The use case provides for expert searches across multiple internal RtQ repositories on any number of topics. These topic searches should be continually refreshed as new content is added to their RtQ databases. (See Exhibits 1-2.) The objective is to eliminate the need for time-consuming and often incomplete classification of RtQ documentation and be able to produce relevant, focused content from documents, rather than requiring the user to read the entire document. A very limited application, but one that returns rapidly on the investment.
Implementation planning
Another narrow use case is to apply analytics to RIM metadata to improve planning algorithms. This is particularly attractive for the change control and variation management process. (See Exhibit 3.)
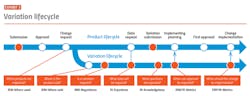
Companies wishing to implement voluntary manufacturing changes face several hurdles even prior to submitting variations. They must understand impact to products and registrations. Intelligent analytics leveraging registration data and business rules engines can provide insight regarding both the need to file a variation with a specific health authority, and the information to be included should a variation be required.
Once variations have been submitted, companies must then decide when to implement the change. Unless mandated by health authorities, implementation timing can depend upon many factors: local requirements, safety stock, and an understanding of when the various health authorities are expected to approve variations and with what conditions of approval.
Using machine learning and predictive analytics to provide continuously updated insights into these factors will allow manufacturing teams to gain greater confidence in planning product change implementation.
Visibility across the ecosystem
Many companies complain about latency in their global ecosystem. These are delays related not to process bottlenecks, but to the time it takes to transfer critical information from one party to another. In one extreme case, it took more than a month for an approval in a local market to be entered into the RIM system, which in turn held up release of the product. One month of lost revenue. One month that patients were denied the therapy.
A recent Grant Thornton survey revealed that some companies have SOPs requiring that no more than five days elapse from receipt of correspondence to entry into the system of record. And even though that seems overly generous, the companies report that there is no way of monitoring or enforcing the SOP.
Our final use case is a simple RPA scenario: using robots to copy and forward specific types of correspondence from affiliates and distributors to a central processing team. Latency is removed and all parties have visibility into the interactions. Business rules determine what can be acted upon and in what manner. Strict controls need to be in place. And there are cultural issues that need to be addressed. But imagine “real-time” visibility with no extra effort.
Building upon the use of RPA to collect the correspondence, ambitious companies could iterate by applying machine learning and automating data entry into RIM or other systems. But perhaps we are straying from the primary message: Start small and achieve measureable and impactful success.
Pharma companies have many opportunities to apply artificial intelligence. One key to success is to apply AI judiciously and achieve rapid improvement, delivering value to both patients and shareholders.