Solving problems at ‘the speed of now’

The unprecedented market conditions of 2020 have made agile operations the new imperative for pharmaceutical manufacturers. Flexibility in scheduling and manufacturing capacity, as well as the ability to respond in near real-time to constraints — whether in raw materials, quality issues, operator availability or asset reliability — are requirements of the new normal.
From primary research to production (Exhibit 1), pharma organizations are seeing an increased need to empower scientists, engineers and operators to make data-driven decisions. However, the existing data and IT infrastructure for many companies does not support this level of adaptability. It is simply not possible when data is trapped in silos, analyses are being done in Excel and collaboration is happening via email.

Cloud-based data storage and analytics present a solution for enabling access to data across the tech transfer stages, creating diagnostic and predictive insights, and harnessing machine learning innovation for production optimization at scale. This addresses the issue of storing petabytes of available data, the variability of this data and the problems that need to be solved at “the speed of now” — all of which add up to too much complexity for humans working alone with spreadsheets.
As organizations adopt cloud-based innovation for advanced analytics — the benefits include improved cycle times, reliability and yield — along with quicker time to market for faster returns on R&D investments. Some of the common use cases for analytics at various stages of scale-up include quality by design modeling, verifying quality with golden profiles, continued process verification and batch monitoring and reporting. Finally, pharma manufacturers are focused on achieving and exceeding corporate sustainability goals including waste reduction, energy consumption improvement and securing the health and safety of their workforce as more employees work from home and teams are distributed.
Defining the issues
The first challenge that global manufacturers need to tackle is data access. On-premise data, while large in volume and with potential value, is stored at the plant level in data silos. This creates significant barriers for making this data available to the right people at the right time to act based on trends and insights, most of which are currently hidden from view.
Beyond siloed storage, there is the issue of getting insights from data. Applications for data historians have been designed to work with real-time process control systems, but trending applications are not designed for the advanced analytics or global operational reporting required for agile operations.
Pharma companies typically rely on business intelligence (BI) applications to extract more value from relational data, but BI applications aren’t purpose-built to handle process time series data. And spreadsheets aren’t ideal for global operational reporting or near-real time decision-making (Exhibit 2). Therefore, none of the existing application solutions are sufficient to meet today’s needs.
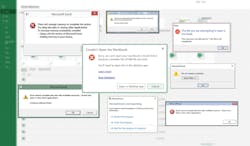
Exhibit 2: Spreadsheets weren’t designed to handle the data volumes and complexities inherent to advanced analytics efforts.
To address these challenges, pharma manufacturers have turned to the cloud for data storage — bringing data from business, lab and manufacturing systems together in a cloud data lake to address access issues. This allows data access to be democratized across an organization by putting all the data in one spot, leveraging the scale and global availability of the cloud.
This approach supports the goal of many chief information and digital transformation officers to generate value chain efficiencies with a common data model for optimizing every stage of the manufacturing process, from raw material to product shipment. That said, the initial IT investment required to achieve data movement and aggregation in the cloud can be high. In some cases, IT-driven initiatives to create cloud data lakes are met with resistance from operational technology (OT) teams concerned about data protection and security.
There are also issues with leveraging advanced analytics to improve operational performance by finding insights in the aggregated data. Advanced analytics requires three attributes for implementation success:
- Access to any and all relevant data associated with investigation;
- Applications to enable process engineers and subject matter experts (SMEs) to tap their knowledge of the plant, processes and assets;
- Support for collaboration and distribution of insights across the organization to enable rapid data-based decision making.
Solving problems using modern cloud technology
Adoption of the cloud is not one-size-fits-all: There are different stages of cloud adoption across the industry. The most advanced companies are using industrial data lakes combined with self-service analytics applications, empowering employees to solve production problems creatively and rapidly. There are four additional models for leveraging cloud-based computing.
The first is quick start analytics where analytics applications, purpose-built for process data, are deployed in the cloud, accessible to users from a web browser and connected to on premise data historians.
Next is “lift and shift,” or moving archival historian data to the cloud so the data is more accessible and available for users anywhere in the organization.
Third is continuous process data movement to cloud, sometimes called streaming data processing. In this scenario, a near-real time flow of process data from the historian is ingested into the cloud, enabling updated production monitoring dashboards across dozens of sites and hundreds of batches.
Last is pure Industrial IoT, where sensor data is piped directly from the assets or a production line to the cloud with no on-premise storage of data.
Whichever method works best for an organization, the need for self-service analytics applications that empower SMEs — those employees who know the data and processes best — is essential for all of these scenarios. Otherwise, an organization may have moved data to a more accessible place, only to find no value was created.
Specific examples of requirements for advanced analytics solutions include the ability to connect to data, find tags quickly, cleanse and contextualize data, diagnose issues and predict future asset and process performance. Then with insights in hand, users need to easily share their work and collaborate with colleagues across different business units and distributed teams. In today’s world of remote work, this is made easier if each user is working with a browser-based, secure application, with no need to use a VPN for connection to a corporate network.
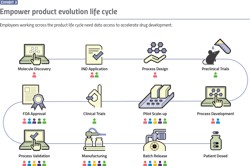
A critical requirement is the ability to connect to all data sources from the same application, across all tech transfer stages, so product lifecycles can be accelerated and improved (Exhibit 3). The goal is to empower teams so they can generate insights quickly — in minutes or hours instead of months. This degree of acceleration is only possible by simplifying the integration of existing systems, and by using the compute horsepower and scalability of the cloud.
As insights are generated, it is also important to implement knowledge capture systems. Analytics applications must enable user annotation, journaling of analysis steps and documentation of text-based notes or diagrams so knowledge is shared easily and does not get lost when employees change roles or leave the company.
Finally, modern cloud solutions need to democratize machine learning innovation. There is tremendous benefit to be gained by empowering engineers with point and click-based prediction models, and with regression or other statistical methods, all transparent to the user. These solutions must be easy to apply because without industrial context in the form of SME insights, their value may be lost, or the results not trusted by the people who are supposed to take action.
Today, many engineers coming to industry directly from universities already have coding skills in Python, R and other advanced languages. These new employees want to apply those skills to advanced analytics, a desire that should be encouraged and enabled. At the top end of the continuum, data science and centralized analytics teams want access to process data, and process teams need to work collaboratively and scale out the impact of their efforts across the enterprise.
Analytics in action
One example of accelerating speed to market is a large molecule pharma company that was finding it difficult to reduce the time involved in pinpointing which pilot drug batches had the best opportunity for commercial production.
Batches do not always maintain integrity as they scale from R&D to pilot to commercial production, and the company’s scientists were struggling to predict cell growth at scale, especially using laboratory and pilot data from different historians and databases. They needed a way to accelerate the scale-up process for promising new monoclonal antibodies.
Previously, the engineers would export all the data from the different sources into Excel spreadsheets and try to overlay it, a very time-consuming process. Then, they would calculate scale-up factors such as agitator power per unit volume or oxygen sparging rate. Using spreadsheets for this analysis was too difficult and cumbersome.
Using cloud-based analytics, company engineers were able to combine lab and pilot plant data from different historians to visualize trends. They were also able to quickly calculate scale-up metrics, batch KPIs and performance measurements for each experiment.
The team was able to efficiently determine differences among batches, compare results of various measurements and experiments and document all findings in electronic journals. This enabled easy collaboration to refine results, improve designs for future experiments and compare results during scale-up.
For example, the technology transfer team can now integrate oxygen sensor measurements to calculate cell-specific oxygen uptake rates for the laboratory and pilot scale to predict the cell growth curve for scale-up. Those values, coupled with other scale-up factors such as oxygen sparging and agitation power, define the scalability of the cell culture as it moves toward commercial production. Cloud-based analytics applications can now flag deviations in the scale-up batches compared to the expected trends to identify potential process limitations.
Faster process development means pharma firms are better able to meet clinical timelines. In this case, a reduction in development time equated to a bottom-line increase of more than $1.5 million.
Use best practices to get started
Getting started with cloud-based analytics begins with defining use cases and working backwards to the required technologies, applications and data infrastructure. Once these use cases and user stories are defined, pharma firms should start small by gaining buy-in for one analytics success on a single batch. This will enable the team to iterate, and to then drive decisions on data governance such as asset hierarchies, so the analytics can be scaled, for example to all batches or all assets in a class.
Finally, it is best to start analytics efforts using existing data, wherever it is stored. Moving, copying or aggregating data shouldn’t be the first step because this can create an overly complicated technology infrastructure. Better decisions regarding infrastructure can be made after a few use cases are proven and a keen sense of requirements is gained. Ideally, advanced analytics efforts should begin before data movement to prove the value of the proposed endeavor.
`