Transforming Data into Information: An Engineering Approach
Patients, doctors, nurses, and regulatory agencies continue to express frustration over the cost of pharmaceutical products and the industry’s inability to control its contribution to the cost of healthcare. Despite ongoing discussions about risk management within the industry, drug manufacturers do not tolerate risk, or change, very well. For example, they may fail to invest in systems improvements though they have long-term goals of reducing overall costs. They often have trouble justifying the implementation of new technologies.
In their defense, these manufacturers undergo more scrutiny than those in most other manufacturing industries, due, in part, to past instances of poor quality control and compliance, such as those which resulted in the Barr decision in 1993 [1]. Lately, however, regulatory agencies around the world have encouraged drug manufacturers to manage risk more effectively and move to 21st century methods of R&D and manufacturing, embodied in FDA’s recently revised process validation guidelines, and ICH Q8-10, often referred to as FDA’s Quality by Design (QbD) guidelines. But even with passionate support, cultural change has been slow to take hold in the industry [2].
One hypothesis used to explain this resistance to change is a lack of guiding examples on the value of knowledge generation and management. Some companies are beginning to formulate knowledge management strategies to support a QbD approach, but to be effective such strategies will require a well-designed set of integrated tools [3]. Within the past 20 years, IT tools have become available to help transform data into knowledge, but they often represent point solutions to small pieces of the problem. The perceived costs of customization, integration and implementation have fueled the industry’s aversion to risk, which has prevented or limited implementation.
In this article, we present an engineering approach to help transform data into information, and subsequently, knowledge.
This approach removes the manual data integration steps required from the lab and plant to regulatory filings and quality assessments. By adopting a long-term, well-engineered strategy for knowledge creation, generation and retention, we believe that the pharmaceutical industry can improve the value that it presents to healthcare.
ANSI/ISA Standards
Knowledge management has been an elusive goal for the industry, even though it can clearly provide significant competitive advantages [4]. A manufacturer has plenty of knowledge about a medicine, but it may not be able to organize that knowledge in a manner that can be understood throughout the organization. The sheer volume of data gathered on a product can exceed billions of discrete data points across isolated systems associated with various parts of the supply chain. These systems may describe materials, equipment, quality control test results, development of quality control methods, and process data generated in development and commercial organizations.
Yet the isolated data systems reveal a significant opportunity if appropriately integrated in a common, system-independent, flexible data model. Even acknowledging this fact is a large step towards an enterprisewide architecture that can positively impact an organization’s capabilities and flexibility [5].
Fortunately, industry standards (ANSI/ISA–88 and ANSI/ISA–95) [6] have been developed to address this problem. These standards were designed specifically for process plant data, but can be applied to analytical and business enterprise processes. When process plant, analytical and business enterprise data are modeled together, they provide a framework to deliver enhanced knowledge management.
However, data standards alone will not achieve the ultimate goal of knowledge management, if the discrete data points aren’t well managed. A data warehousing approach solves that challenge by providing a system-independent data storage mechanism.
Data warehousing is a mechanism that routinely takes discrete data, aggregates it into information by associating it with context or metadata and reports to a variety of consumers and investigators via a common integrated data source.
ISA-88 and ISA-95 describe people, materials, and equipment and sequentially coordinate these resources into a recipe that can be executed to produce a product. They are generic enough to work across many industries, and have been successfully implemented in process control systems (PCS), data historians, manufacturing execution systems (MES), and ERP systems.
So far, however, these standards have not been applied to such pharmaceutical-specific systems as electronic laboratory notebooks (eLNs), laboratory information management systems (LIMS), or computerized maintenance management systems (CMMS). Through direct collaborations with system providers, the adaptation of these standards is proceeding and enabling smoother transfer of information. Many providers are acknowledging that secure execution is no longer an appropriate benchmark. Rather, the new benchmark is the flow and context of information.
In building a data warehouse within development, precautions must be taken to ensure that the work adheres to the spirit of the regulations from a risk-management, patient safety and value perspective. Combining ISA-88 and ISA-95 data standards for workflow execution with a data warehousing strategy [7] offers the required flexibility for a long-standing knowledge management strategy. We call this approach the “Recipe Data Warehouse” strategy.
Recipe Data Warehousing
The Recipe “Data” Warehouse is so named because it combines the knowledge management strategy of data warehousing and the modularity of recipes (ISA-88 and ISA-95). The data warehousing strategy presented in Figure 1, commonly known as the “Kimball Model” [8], breaks the process into discrete functions. Aligned with good engineering approaches, a design is chosen to isolate and modularize a larger process into smaller functions to help isolate risks and enable scalability.
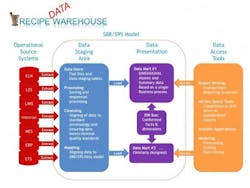
Figure 1. The Recipe Data Warehouse
Basic elements of the data warehouse [8, pg 7]. The operational data sources presented here are typical of a pharmaceutical development environment where you have: Electronic notebooks (ELN), Lab Execution Systems (LES), Lab Information Systems (LIMS), Data historians (Historian), Manufacturing execution systems (MES), Enterprise resource planning (ERP) and Event Tracking Systems (ETS). The list is not meant to be exhaustive, but simply demonstrate the scalability of taking a Kimball-based approach.
The operational source systems are the transactional systems that capture the raw data resulting from workflow execution. These operational source systems should be left isolated to maintain solid system boundaries. It is critical to align with the ISA-88/ISA-95 data model as much as possible to minimize the amount of work required in extracting, translation and loading (ETL) data to the warehouse. It is also helpful to work directly with the source system vendors, since much of the effort involves simply configuring the workflow execution systems with a recipe framework.
The data staging area is where most of the work in data cleansing, sorting and translation to the standard ISA-88/ISA-95 data model occurs. It is important to take time to design this model to have appropriate data constraints to help ensure data integrity. The model is essentially built to enforce data integrity, whereby data is rejected if certain standard referential data is not provided. This can be viewed as a data quality layer.
The data presentation area is subsequently used to preassemble data from the data staging area to optimize performance on data extraction as well as to drive standards on reporting. The data presentation area can be quite flexible. Data from the staging area is presented in facts and dimensions, formally known as star schemas, which have been optimized for faster data retrieval.
The reporting layer ranges from standardized reports or portals to ad hoc reporting, data mining/visualization and/or modeling. It is important to note that the reporting layer should be independent of the data mart, as it is common to have multiple reporting options for a common data set.
Reality: Janssen’s Project
Because the drug development cycle takes several years, implementing such a system is not as simple as installing software and training. First and foremost, an organization must be willing to take ownership of the project. It must figure out how to piece together the data so that it provides information and results in actionable knowledge that can subsequently be used to support the sequential steps of research.
To accomplish this goal at Janssen, we began by designing an ISA88 and ISA-95 compliant database, following best practices for database design. The database provided a common and flexible location to start loading recipe-based data.
Since no data collected to date had complete recipe context, we used an ETL process, with standard industry tools, to extract data, translate it into a recipe context and subsequently load it into the Recipe Data Warehouse. This approach will be necessary for anyone implementing a comprehensive knowledge management strategy, as legacy information is combined with data associated with the new recipe master data. Again, this is a benefit of choosing the Kimball-based model, as data sources can change as a function of time.
The first step in our transformation of information to a recipe format was the alignment on a common process definition, typically referred to as a platform recipe. The platform recipe helps ensure the appropriate taxonomy of the data. Once the platform recipe was provided, the exercise of transforming data from a variety of source systems could occur. The platform recipe provides a checklist of all information required, and the source systems can fill in the blanks.
Aggregation and Visualization
The real power of this effort lies in the data visualization capabilities. Presented here are two examples of how the Recipe Data Warehouse approach enables scientists and engineers to analyze impacts of final product quality attributes to in-process and raw material inputs.
Figure 2 shows a solid-dosage formulation example, where the in-process granulation can affect final product, demonstrating how the fines in the granulation can impact dissolution and tap density.
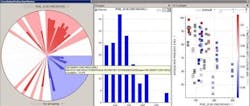
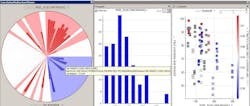
Figure 2. Solid Dosage Formulation Example
The correlation pie chart on the left hand side shows what parameters are associated with the fines in the samples [PSD_D10 (Microns)]. The distribution of the fines particle size is shown in the center and finally the effects of these fines on final product attributes (i.e., dissolution).
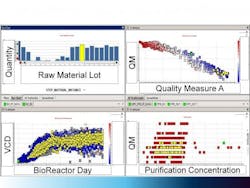
Figure 3. Large Molecule Process Example
The figure shows an integrated view of a large molecule process example, where raw material inputs are linked to bioreactor performance, purification and finally to the final product quality attributes. All data in the four panes shaded in yellow are interconnected. The “Control Panel” enables scientists to interact with the data sets to develop and refine hypotheses related to troubleshooting processes. This helps to transform from data collection to data consumption and proactive capabilities.
Figure 3 shows a large-molecule example, where the final product quality attributes are linked to the raw materials as well as subsequent bioreactor and purification processes. The Recipe Data Warehousing strategy provides scientists and engineers with the integrated data set to help understand impacts of variables on the process.
A solid engineering approach to knowledge management is required to bring the pharmaceutical industry into the 21st century. The ISA-88/ISA-95 data standards and data warehousing strategies provide one way to achieve a manufacturer’s ultimate value and knowledge management goals. The process takes time, and care must be taken to drive standardization as much as possible throughout the information pipeline, especially the data source systems (transactional systems). But with time and effort, a Recipe Data Warehousing strategy can enable knowledge management and subsequently accelerate an organization’s ability to develop novel medicines for patients.
Acknowledgements
Thanks to colleagues and collaboration partners for contributions to this project. We would like to specifically thank Dimitris Agrafiotis, Ryan Bass, Walter Cedeno, Remo Colarusso, John Cunningham, Nick Dani, John Dingerdissen, Larry Doolittle, Peter Gates, Joel Hanson, Ed Jaeger, Marijke Massy, Pascal Maes, Steve Mehrman, Don Neblock, Lief Poulson and John Stong.
References
1. http://biopharminternational.findpharma.com/biopharm/article/articleDetail.jsp?id=470169&sk=&date=&pageID=6
2. McKenzie P, et al. “Can Pharmaceutical Process Development Become High Tech?” AIChE Journal 2006 Vol. 52, No. 12, 3990- 3994.
3. Junker B, et al. “Design-for-Six-Sigma To Develop a Bioprocess Knowledge Management Framework” PDA J Pharm Sci and Tech 2011, 65: 140-165.
4. Pisano, G. P., “The Development Factor” Harvard Business School Press, 1997: Chapter 1.
5. Miller, T. E., Berger, D. W. “Totally integrated enterprise: a framework and methodology for business and technology improvement” CRC Press LLC., 2001.
6. a) ISA standard S88.01 “Batch Control - Part 1: Models and Terminology”
b) ISA standard S88.02 “Batch Control - Part 2: Data Structures and Guidelines for Languages”
c) ISA standard S88.03 “Batch Control - Part 3: General and Site Recipe Models and Representation”
d) ISA standard S95.01 “Enterprise-Control System Integration Part 1: Models and Terminology
e) ISA standard S95.02 “Enterprise-Control System Integration Part 2: Object Model Attributes
7. Agrafiotis DK, et al. “Advanced Biological and Chemical Discovery (ABCD): centralizing discovery knowledge in an inherently decentralized world.” J. Chem. Info. Model. 2007, 47, 1999-2014.
8. Kimball, R.; Ross, M. “The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling.” New York, NY, USA: John Wiley and Sons, Inc. 2002.
About the Authors
Paul McKenzie, PhD, leads the Global Development Organization of Janssen Pharmaceutical Companies of Johnson & Johnson.In this role, Paul drives value creation and increases R&D operational effectiveness.He and his teams interact closely with the therapeutic and functional areas leaders, as well as supply chain and external partners. Paul came to Johnson & Johnson from Bristol-Myers Squibb (BMS), where he was Vice President and General Manager of the BMS large-scale cell culture facility in Massachusetts. Prior to this role, Paul was Vice President, Technical Transfer Governance Committee, at BMS, where he partnered with key functional areas to create and oversee the technical transfer of biological, chemical, drug product and natural product processes for new drug candidates, and completed multiple global submissions for new pipeline products. Prior to BMS, Paul worked for Merck in various roles with the company’s large-scale organic pilot plant and Pharmaceutical Development & Clinical Supply pilot plants.
Adam M. Fermier, PhD, is a Principal Engineer at Janssen, where he has been since 1998. He started his career in early development of small molecules, focused on laboratory automation, and later moved into drug product development, where he led a team focused on providing process analytical support for a pilot plant. In 2010 he joined the Strategic Operations group, where he continued to partner on developing the informatics strategy presented here.
Shaun McWeeney is a Principal Engineer in the Pharmaceutical Development and Manufacturing Sciences group at Johnson and Johnson in Spring House and Malvern, Pennsylvania. He is responsible for strategic planning of scientific systems such as Data Warehouse, Electronic Lab Notebook, and others. Previously, Shaun worked as an automation engineer for Siemens Energy & Automation.
Terry Murphy is Janssen’s Director of Systems Implementation, Strategic Operations, Pharmaceutical Development & Manufacturing Sciences. He joined Centocor, a Johnson & Johnson company, in 2005, during the construction of their new Biologics facility in Cork, Ireland. Since then he has held various roles of increasing responsibility, primarily in the Manufacturing Systems space until moving in 2009 to his current role in Pharmaceuticals R&D
Dr. Gene Schaefer is currently Senior Director, API Large Molecule Pharmaceutical Development & Manufacturing Sciences at Janssen Pharmaceuticals, in Spring House and Malvern, Pennsylvania. In this role he is responsible for a number of projects from early-stage process development to commercial product support for protein therapeutics. Previously, he was Director of Process Technologies in the Protein Therapeutics Development group at Bristol-Myers Squibb in Hopewell, New Jersey. He also worked at Schering-Plough in Union, New Jersey, and at Genzyme in Boston and the U.K.